

type
status
date
slug
summary
tags
category
icon
password
📦选择你的部署方式
各自的优势劣势
- 本地部署
- 优点:不需要网络,本地部署,随时可用,没有网络也可以
- 缺点:比较吃配置,配置较低的用起来可能不流畅
- api部署
- 优点:可以体验到满血版的deepseek-r1,性能强劲,还可以作为个人知识库
- 缺点:需要联网,需要联网,需要联网,没网的时候用不了
本地部署
1. 查看电脑配置
- 进入任务管理器,
ctrl+alt+delete选择任务管理器/桌面右键任务栏空白-点击任务管理器
- 依次点击性能-gpu,查看本地gpu型号以及gpu显存
- 显存小于8g的笔记本,不建议本地部署,推理能力不强,不如app/官方网站/api
- 如果真的想试试,可以在本地跑
1.5b,后面有方法
- 显存大于等于
8g的,找到最接近自己显存的模型就可以了
- 例:
8g显存可以部署7b、8b12g显存可以部署14b玩儿玩儿,再往上就不建议了,跑起来会很卡
- 市面上大部分的显存都在
8g12g16g左右
- 如果真的想体验最原生态的,最接近
GPT-o3-mini的,还是推荐使用api哈

2. 下载模型管理器-ollama
官方地址:

虽然官方不需要科学上网也可以进入,但是下载跳转的是GitHub,所以我这里提供一个下载地址:

3. 修改本地模型存储位置
因为模型默认会下载在c盘,所以我们这里修改一下模型的下载位置


选择下面的系统环境变量并新增
OLLAMA_MODELS
选择浏览目录,并将模型放在一个自己喜欢的位置之后,点击确定保存

⚠️:尽量先修改模型位置(环境变量)后去下载模型,要不然默认会下载在c盘中
4. 下载自己需要的模型
进入ollama官网,搜索deepseek

我们点击deepseek-r1并进入后,会显示一个页面

点击左边会发现有不同的模型,他们分别对应了不同的大小,也就意味着他们的模型数量不同,推理能力也不同,我们按照上面提到的,根据自己的电脑选择不同的模型大小

5. 安装模型
- 打开控制台
win+R,输入cmd打开控制台(之前下载好的时候应该也会弹出控制台)
- 双击下载好的ollama,确保后台已经打开,否则会没有办法使用

- 在控制台中输入
ollama -h
如果出现如图所示,则代表我们的模型管理工具已经装好了

- 在控制台中输入:
后面的参数就是你想安装的模型大小
- 之后测试本地模型是否可以使用

退出请输入
/bye当出现这种情况的时候,就代表我们已经安装成功了,之后我们进入客户端页面
api部署
我们这边使用硅基流动来使用我们的deepseek-r1-671b模型(满血版deepseek)
- 注册账号
点击上面的链接,进入硅基流动官网进行账号注册(不需要实名认证也可以使用)
- 注册好以后,进入模型广场

我们可以在这里看到很多开源大模型,他的优势就是,他把模型跑在他们的机房,我们只需要调用api就可以使用他们的算力了
我们注册好以后,会赠送2000万Tokens,约等于
¥14,够我们用很久很久- 点击API密钥并新建密钥

- 新建密钥后留在当前页面/把密钥复制出来
- 进入客户端
选择你的客户端
这里我给你们提供的客户端是
cherry-studio,当然很多人都推荐的是chatBox,这个看个人选择ChatBox


1. 下载本地客户端并安装,安装后启动

2. 选择使用自己的api或模型

3. 使用本地deepseek模型
3.1. 选择ollama API

3.2. 选择我们刚刚安装好的本地模型后保存

3.3. 和本地模型进行对话

⚠️:全程不要退出ollama,否则会出现无法连接的问题
4. 使用硅基流动的api
4.1. 点击设置-模型提供方-添加自定义模型提供方

4.2. 设置自己的api密钥
- 名称(比如可以是 硅基流动,方面后续使用区分)
- API 域名填写:
https://api.siliconflow.cn/
- API 路径填写:
/v1/chat/completions
- API 密钥:填写在
SiliconCloud后台新建的 API 密钥

4.3. 模型名称
我们进入模型广场

点击我们需要的模型,并复制模型名称

将名称粘贴到👇这个里面并保存

4.4. 与硅基流动api对话

CherryStudio

1. 下载并安装客户端
2. 硅基流动api设置
2.1. 选择硅基流动并启动(右上角启动按钮)

2.2. 粘贴好api后,我们点击管理,添加deepseek-r1

2.3. 点击测试,并选择deepseek-r1

2.4. 提示链接成功,我们就可以直接使用了

2.5. 进入聊天页面,选择自己需要的助手

2.6. 进入聊天后,选择自己需要的模型

2.7. 和硅基流动api对话

3. 和本地模型对话
3.1. 选择本地ollama模型,并启动(右上角启动按钮)

3.2. 点击管理,添加本地大模型
注意⚠️:这里只会显示本地已经安装的大模型,如果没有安装是不会显示的

3.3. 点击检查,出现链接成功,代表已经可以使用

3.4. 之后就可以和本地大模型进行友好交流了

写在最后
之所以推荐
CherryStudio的原因一个是因为他好看,第二有许多特色的提示词(prompt),可能覆盖到你日常生活中会用到的大部分内容,所以你可以在创建智能体的时候,选择适合你的提示词,当然,你也可以自定义你的提示词,让他更贴合你的生活/工作场景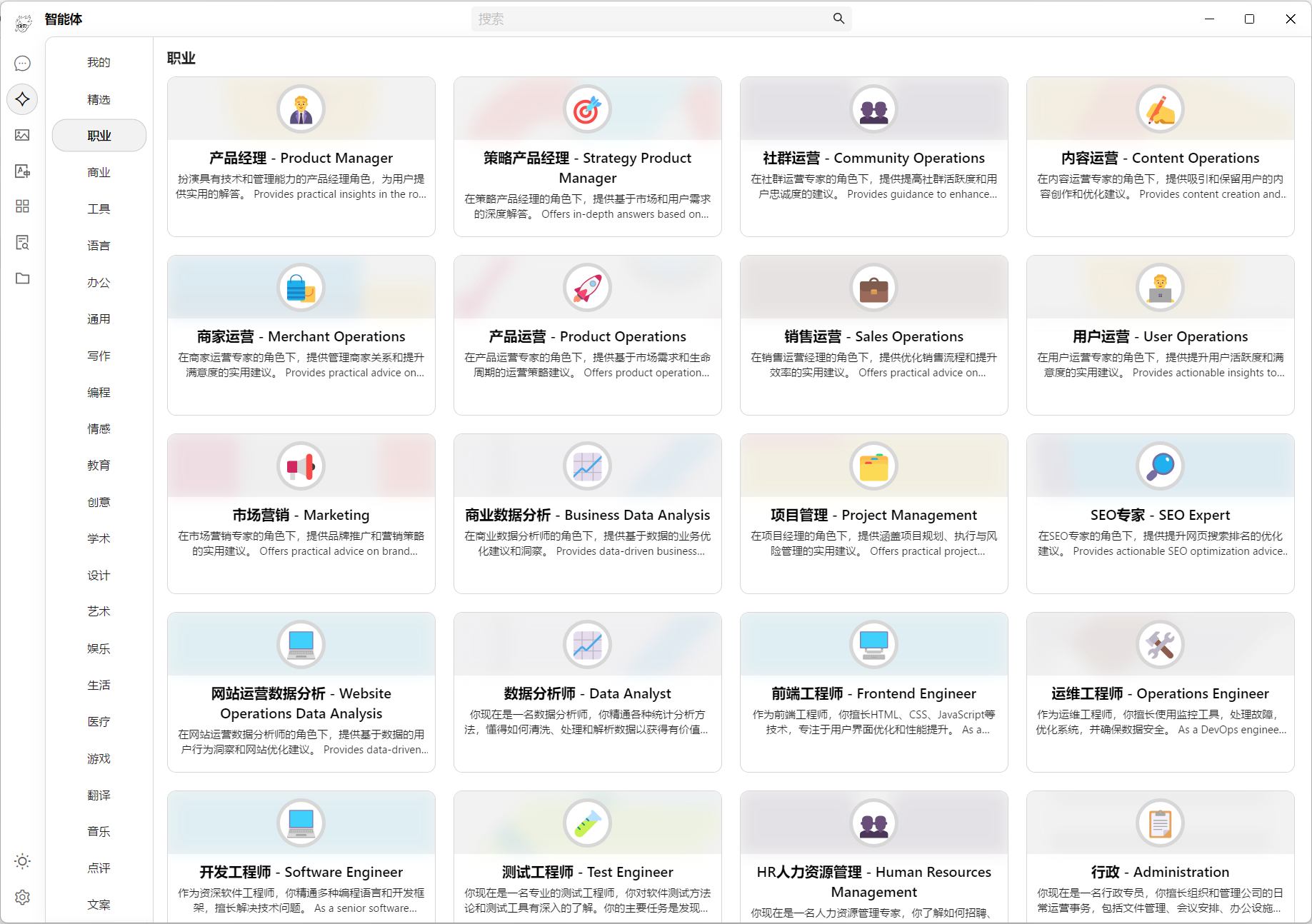
- 作者:阿杜
- 链接:http://try2relax.top/AI/DeployDeepseekLocally
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。

